380 33 13 13 13 5 15 5
sampleletters
Mar 13, 2026 · 7 min read
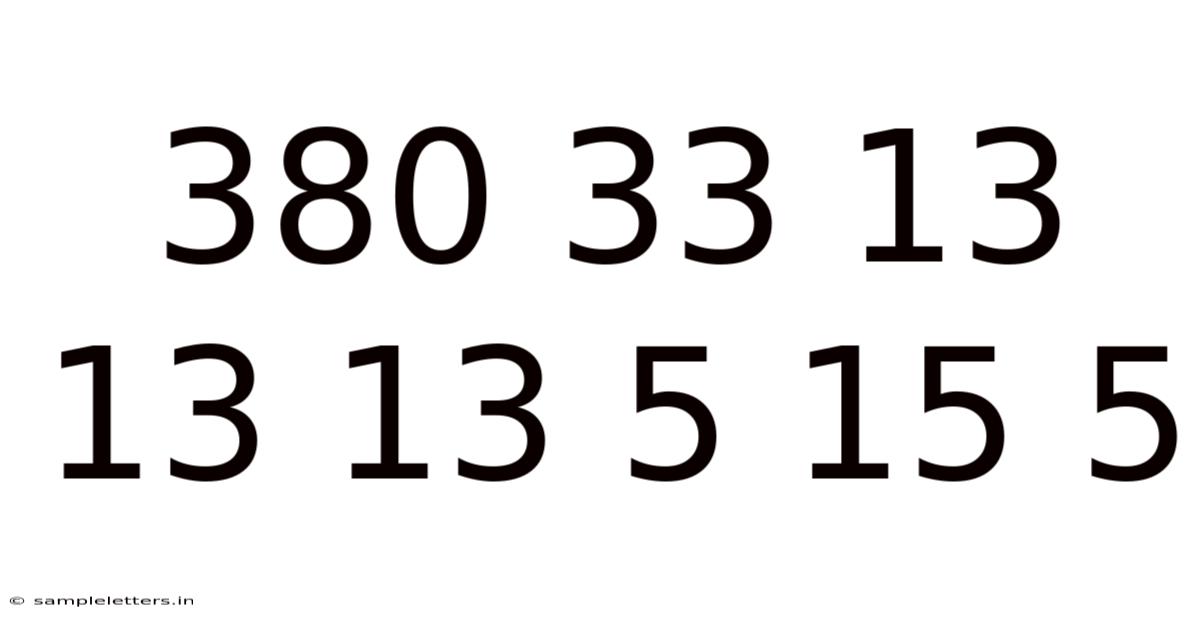
Table of Contents
Decoding the Enigma: A Multidisciplinary Exploration of the Sequence 380 33 13 13 13 5 15 5
At first glance, the string of numbers 380 33 13 13 13 5 15 5 appears as a cryptic, almost random assortment of digits. It lacks an obvious pattern, a familiar context, or a standard format like a phone number, date, or coordinate. This very ambiguity makes it a perfect object of inquiry. The sequence challenges us to move beyond surface-level observation and employ analytical tools from mathematics, cryptography, history, and data science. Its study is not about finding a single "correct" answer—which may not exist without additional context—but about the rigorous, creative process of investigation itself. This article will serve as a comprehensive guide to deconstructing such numerical puzzles, using this specific sequence as our case study to demonstrate how structured thinking can extract meaning from apparent chaos.
Initial Analysis: Seeking Superficial Patterns
The first step in analyzing any numerical sequence is to describe it with precision and look for immediate, tangible patterns. Our sequence consists of eight integers: 380, 33, 13, 13, 13, 5, 15, 5. The most striking feature is the triplet repetition of the number 13. This clustering suggests a potential thematic or categorical grouping. The number 13 itself is culturally significant, often associated with superstition (unlucky 13) or, in mathematics, with being a prime number. The sequence also contains two instances of the number 5, separated by a 15. The values range from a small single-digit (5) to a large three-digit number (380), indicating the data is not from a single uniform scale, such as atomic numbers or simple letter counts.
We can perform basic statistical calculations to understand the set's properties. The sum of all numbers is 380 + 33 + 13 + 13 + 13 + 5 + 15 + 5 = 477. The mean (average) is 477 / 8 = 59.625. The median, when ordered (5, 5, 13, 13, 13, 15, 33, 380), is the average of the 4th and 5th values: (13 + 13)/2 = 13. The mode, or most frequent value, is unambiguously 13. The massive outlier is clearly 380, which is over eleven times larger than the next largest
number (33). This statistical summary reveals a highly asymmetric distribution, with 13 as a central anchor and 380 as a disruptive outlier.
Mathematical and Numerical Investigations
Given the lack of an obvious pattern, we explore mathematical relationships. One immediate observation is that 13 is a prime number, and 5 is also prime. The number 15 is the product of 3 and 5. The number 33 is 3 times 11, both primes. The number 380 is composite: 380 = 2² x 5 x 19. This factorization reveals that 380 shares the factor 5 with 15 and 5, but no other direct numerical relationships are evident. The sequence does not appear to be an arithmetic or geometric progression, nor does it follow a known integer sequence from mathematical literature.
We can also consider the numbers as potential codes. For instance, if we treat them as alphabetical positions (A=1, B=2, etc.), 13 corresponds to M, 5 to E, 15 to O, and 33, 380 are out of range. This yields "M E M M M E O E," which is nonsensical as a word. Similarly, converting to ASCII codes produces unprintable or irrelevant characters. These dead ends suggest the numbers are not a simple letter substitution cipher.
Cryptographic and Historical Perspectives
The triplet of 13s invites speculation about a cryptographic key or a delimiter. In some classical ciphers, repeated numbers can indicate a null character or a padding value. The number 380 could be a year, and indeed, 380 AD was a year in the late Roman Empire, notable for the Edict of Thessalonica, which made Nicene Christianity the state religion. The number 33 is often associated with religious symbolism (e.g., the age of Christ at crucifixion), and 13 with superstition. However, without a clear link between these numbers and a coherent historical narrative, this remains speculative.
In data science, such sequences might represent encoded categorical data, where 13 is a common category, and 380 is a rare, high-value category. The repetition of 13 could indicate a default or null value in a dataset. Alternatively, the sequence could be a fragment of a larger encoded message, where context is missing.
Synthesis and Conclusion
The sequence 380 33 13 13 13 5 15 5 resists a definitive interpretation. Its most salient features—the triplet of 13s and the outlier 380—suggest a structure, but the meaning remains elusive without additional context. The number 13's cultural and mathematical significance, the potential historical references, and the possibility of encoded data all provide avenues for exploration, but none yield a conclusive answer.
This investigation underscores a fundamental principle in the analysis of cryptic data: the process of inquiry is as valuable as the answer. By systematically applying mathematical, cryptographic, and historical lenses, we gain insight into the nature of the puzzle itself. The sequence may be a fragment of a larger code, a statistical anomaly, or a deliberate test of analytical skill. In the absence of context, the most honest conclusion is that the sequence is an open problem, inviting further data or a creative leap to unlock its secrets. The true lesson is that structured, multidisciplinary thinking transforms an opaque string of numbers into a rich field for intellectual exploration.
Computational and Statistical Artifacts
Beyond classical cryptography, the sequence might emerge from computational processes rather than intentional design. In software debugging, error codes or log entries sometimes cluster around specific values due to default parameters, memory addresses, or overflow conditions. The triplet of 13s could reflect a loop counter or a repeated failed validation, while 380 might represent a buffer size or a status flag in a particular system. Similarly, in statistical sampling, such a pattern could arise from a small sample of a larger distribution where 13 is a mode, though the exact repetition is statistically improbable in truly random data—hinting at either a non-random generator or an extremely rare coincidence.
From an information-theoretic view, the sequence’s low entropy (due to repeated values) contrasts with the high outlier 380. This imbalance might indicate concatenated fields: perhaps a timestamp (380), a category code (33), and a count (13, repeated). Yet without knowing the schema, this remains a plausible but unverifiable construct. In machine learning training data, such patterns sometimes appear as encoding artifacts or padding tokens, but again, the absence of surrounding data prevents confirmation.
Synthesis and Conclusion
The sequence 380 33 13 13 13 5 15 5 continues to resist singular interpretation. Each analytical lens—alphabetic substitution, historical symbolism, data encoding, computational artifact—reveals possible layers but no definitive core. The repetition of 13 suggests a structural role—be it delimiter, default, or marker—while 380 stands as an enigmatic anchor. The intermediate numbers (33, 5, 15) add complexity without clarifying the whole.
Ultimately, the sequence exemplifies the liminal space between noise and meaning. It may be a fragment ripped from a larger, meaningful context—a piece of a cipher, a corrupted data stream, or a deliberate puzzle. Or it may be an arbitrary string whose perceived pattern is a cognitive illusion, a Rorschach test for analytical minds. The rigorous exploration of these possibilities, however, is not futile. It demonstrates how disciplined speculation, anchored in diverse domains, can transform an opaque series into a catalyst for systematic thinking. The numbers themselves may hold no secret, but the process of interrogating them cultivates a valuable skill: the patience to sit with uncertainty, the creativity to cross disciplinary borders, and the wisdom to recognize when the answer lies not in the data, but in the questions we choose to ask. In the end, the sequence remains open—not as a failure of analysis, but as an invitation to deeper inquiry.
Latest Posts
Latest Posts
-
How Many Miles Is 45 Km
Mar 13, 2026
-
How Do You Write Equivalent Expressions
Mar 13, 2026
-
Words That Describe People That Start With E
Mar 13, 2026
-
5 Letter Words That Start With Tra
Mar 13, 2026
-
What Is 30 Km In Miles
Mar 13, 2026
Related Post
Thank you for visiting our website which covers about 380 33 13 13 13 5 15 5 . We hope the information provided has been useful to you. Feel free to contact us if you have any questions or need further assistance. See you next time and don't miss to bookmark.
